A framework to think about Google's AI worries


“You want to know how to paint a perfect painting? It's easy. Make yourself perfect and then just paint naturally.” - Robert Pirsig, The Zen and the art of motorcycle maintance
In How to build a search engine, I described a very simple model of how to make a search engine:
First, you make a general engine that gives a decent answer for every possible query
Then you optimize every possible special situation

Trying to make a general engine that could be a step function against Google is an insurmountable task, akin to trying to make a monkey recite poetry on a pedestal, but the work in Large Language Models from companies like OpenAI and Meta raises concerns for GOOGL 0.00%↑ bulls (like me) of whether Google moat could be under attack. This doesn’t mean that Google’s being disrupted in the next 5 years or that the risk is high, just that one should interpret this as “bad for Google” and try to describe the magnitude.1


How bad is it for Google? Not much, but it’s certainly bad. Let’s discuss
Do not talk about revenue
I’d like to address an important issue before going on: the financials don’t matter and the monetization doesn’t matter. When you’re analyzing consumer internet companies, you shall focus on the fundamentals, and the fundamentals are usage because they are better leading indicators of earnings power than current financials.
Companies are worth billions without ever making revenue, and I mean worth for real, the kind of wealth you can buy yachts (or at least rent yachts?).
YouTube was acquired for $1B by Google in 2005 without any sales
Instagram was bought for $1B by Facebook in 2012 without any revenue
Twitch was acquired for $970M by Amazon in 2014 with $32M in revenues
WhatsApp was acquired for $18B by Facebook in 2014 with insignificant revenue2
Financials lag. ByteDance has a similar valuation to Meta, around $300B, despite making a quarter of the revenues and not turning a profit. But people know that ByteDance is underearning and that the monetization of the north of 2B users that they have will eventually be figured out.
But when you’re analyzing from the incumbent’s perspective, a new worse business model can emerge and make a dent in your business, like messaging apps like Telegram can take lots of usage from social media like Facebook without making lots of money themselves.
So you should not worry whether OpenAI, Neeva, or any other upstart can make a lot of money with their competitive offerings to Google. Of course, they need to pay their bills, but this can happen in many many ways without either the investors or the founders of those companies appearing on the Forbes list.
Google hierarchy of moats
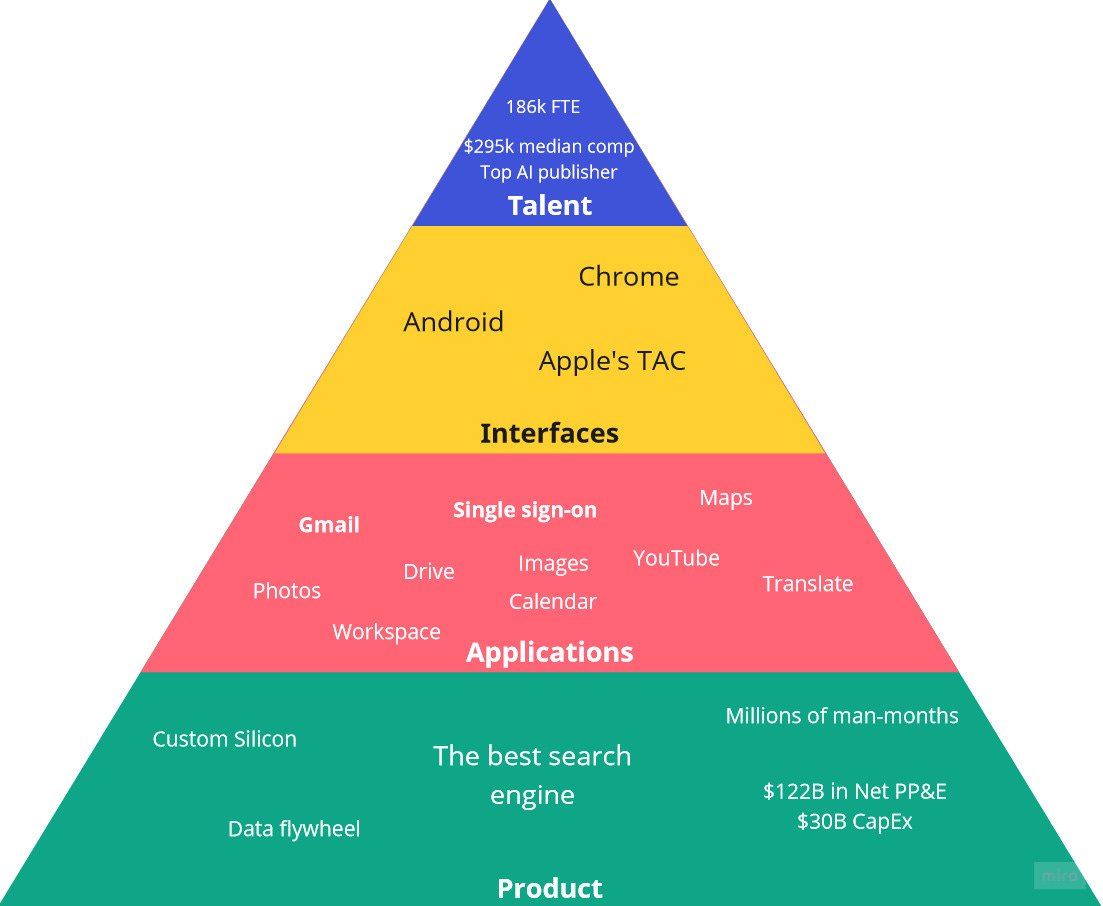
Similarly to Maslow’s hierarchy of needs, I’d like to introduce a hierarchy of moats for Google. I think this will help to structure the debate in the investing community on how to think about Google's competitive advantages.
The lower in the pyramid, the more fundamental these aspects are. The parts on the top half are enabled by the bottom half, meaning that the moats that are attacked first are those in the bottom. Also, the moats in the bottom are the strongest.
Infrastructure
This is the part of objectively being the best product in the market. The most important thing is of course to give the best answers for all queries when used. As you can imagine, no one will start by hiring 186,000 employees or by making a Drive competitor (sorry, Dropbox) so they integrate backward into search. This can be a way to compete with Disney: first, you make a video rental operation, and 25 years later Disney is firing their CEO because your shows are better than theirs. But it’s search, not movies, and here customers will want the best option because they only use one search engines and there’s no differentiation beyond giving the best answers.3
Another issue is that even if you have great technology, like a next-gen LLM, you still lack Google’s data. User data is a heuristic to know which sites have good answers and which ones have bad answers. But perhaps this advantage can be less important in the very smart AI world: you can feed the top 100 sites and ask it to summarize or rank them, without human intervention. Don’t get me wrong, I still think the network effect is very big, but it seems it is slowly losing its importance and people overestimate it.
But making a search engine that gives answers significantly better than Google isn’t enough. You’ll need:
Fast answers (milliseconds)
Low cost per answer
High reliability
Lots of optimization for special situations
Google’s first-party data (mostly Maps)
It is possible that if a startup manages to crack the code, make a great prototype for geeks, but the business isn’t viable because of the very high costs. This is a very real issue, it is very expensive to train AI, but also it's expensive to make inference. This Hacker News user who claims to be a Google engineer has a great take.
I work at Alphabet and I recently went to an internal tech talk about deploying large language models like this at Google. As a disclaimer I'll first note that this is not my area of expertise, I just attended the tech talk because it sounded interesting.
Large language models like GPT are one of the biggest areas of active ML research at Google, and there's a ton of pretty obvious applications for how they can be used to answer queries, index information, etc. There is a huge budget at Google related to staffing people to work on these kinds of models and do the actual training, which is very expensive because it takes a ton of compute capacity to train these super huge language models. However what I gathered from the talk is the economics of actually using these kinds of language models in the biggest Google products (e.g. search, gmail) isn't quite there yet. It's one thing to put up a demo that interested nerds can play with, but it's quite another thing to try to integrate it deeply in a system that serves billions of requests a day when you take into account serving costs, added latency, and the fact that the average revenue on something like a Google search is close to infinitesimal already. I think I remember the presenter saying something like they'd want to reduce the costs by at least 10x before it would be feasible to integrate models like this in products like search. A 10x or even 100x improvement is obviously an attainable target in the next few years, so I think technology like this is coming in the next few years.
But there are technology costs outside pure AI silicon costs: networks, CPUs, memory… It’s no wonder Meta is the last big internet company to run its own infrastructure: when they started there was no AWS, so they had to build it on their own. Even AI giant ByteDance is in the cloud. Actually, I’d expect a competing AI-backed search engine to be so computationally intensive that they’d have to sell to Amazon or Microsoft. Even though lots of the $122B Net Property, Plant, and Equipment on Google’s balance sheet aren’t data centers for the search engine, a lot still is and that’s commonly known as way lot of money.
Also, Google has first-party data on lots of things, particularly Maps, that help to protect the business.
Applications
There are other moats around the business outside from infra. Billions of people use Google products like YouTube and Gmail. There are some ways this protects Google:
Branding. If you use Google Drive, Google Maps, Google Travel, Gmail, YouTube, Google Calendar, Google Translate, Google SSO, Google Docs, Google Forms, Google Photos, Google News, Google Meet, and perhaps Google Assistant and Google Images, maybe, just maybe, you can choose Google Search.
Of course, many Apple users will notice they don’t use tons of these services from Google. That is one more reason why Google needs to pay TAC: because Apple is the well positioned to create such a threat.
Begging. If you ever leave Google Search, but not Gmail, Google can see you are alive and ask you to go back (like when you open Gmail with Edge and it asks you to change the default browser). They can be indefinitely annoying here, depending on how desperate they are.
Subsidy. You can charge for these apps if users stop using search. Google is already doing that a bit with Google One, but one could be way more extreme: if people stop using search, you can say Gmail is $8/mo (but it’s less if you do use Google)
The subsidy may seem foolish, but Microsoft does exactly that with Microsoft Rewards. If you use Edge, search on Bing or play on Xbox, you get points that you can trade for gift cards. 17 years in, Microsoft is yet to ask for money for Hotmail (my main account is there), but like Google, it is a carrot they could eventually use.
Of course, anyone can compete with Gmail. But there are significant changing costs for users so they may choose to skip OpenAIMail.
Even though applications can’t protect Google, they can help them to buy second chances. Applications are second on the list because they would be the next thing an upstart would make after solving the infrastructure part.
Interfaces
Google owns two of the three main interfaces from which they distribute their product. The fact they paid $50M for Android and they internally built Chrome is a very underrated business win because they had no right to win these markets. They won by pure great business acumen. The fact that Google is the default on all smartphones and all main browsers except for Edge not only helps to crush the competition technologically (particularly in a pre-AI era, where consumer search data is incredibly useful) but also helps to establish consumer habits and Google as a synonym of search. Even if Google were forced to divest Android and Chrome, and stop paying Apple, the damage is already done and 20 years of consumer habits are hard to displace.
It’s likely that any upstart wouldn’t be able to own any of these interfaces, given how expensive it would be to own them. Google employs 10,000 people in Chorme and Android. If God forbid they ever lose leadership, Google could still make a living collecting TAC for Android and Chrome.4
The risk here for Google is that AI-based challengers rise at the same time they face serious regulatory headwinds. Even under these circumstances, any challenger would need to ask consumers to manually change search preferences for a very long time. This would work for innovators and early adopters, but it’s hard to see how you bring the late majority and latecomers.
Talent
Google’s hundreds of billions of dollars in revenues allow them a simple strategy: hire a lot of AI scientists and ask them to research any problem that it’s not how to make a competing search engine to keep them busy and pay very high wages. Of course, you’ll also hire lots of AI scientists to think about search, but that you would do anyway.
Google is consistently the top institution in AI conferences like NeurIPS, for example:

Of course, you don’t need to be that cynical. These people are really smart and they can create real value, like autonomous ride-hailing startups or protein folding software. Even when there isn’t a commercial angle for your software, you can deploy it as a marketing gimmick to hire even more AI scientists: if they all hear that TensorFlow is built by Google and they think that TensorFlow is great, maybe it will help you to hire the best ones and prevent them from leaking to a competitor.
You of course can also buy companies and literally don’t do anything with them for nearly a decade.
Conclusion
Focus on the monkey. Google’s disruptor won’t start by building Android, they’ll necessarily start by addressing the hardest part: core search. Do not dismiss because it doesn’t work properly, try extrapolating the trends a bit to see ahead.
Don’t spend your time asking how great the disruptor’s business will be, as long one can pay the bills, someone will try to compete. Technological progress can destroy economic value. Even if Google continues to dominate, maybe in the new paradigm they need to spend significantly more per user (like what happened with Meta after ATT/TikTok).
Follow the AI training and inference costs progression. As Moore’s Law stalls, lots of AI challenges will be solved just by throwing more silicon at it (Disclaimer: long TSMC). On the other hand, accelerators, ASICs5, and other design solutions can help with the cost challenges to be overcome.
The competition may come from a hyperscaler competitor or Apple. All the FAAMG+N are well-positioned to compete in the event that AI lowers the moats with Google. Also, try not to dismiss a competitor just because of shortcuts, like headcount, Amazon could buy them.
In summary, I’m not significantly worried about it. There are many layers of moats, many technological breakthroughs to be overcome, and questions on how scalable these models can be. We are a long time, maybe more than a decade away from any credible attack against Moutain View.
The most likely outcome is some sort of margin reduction because of increased AI costs. I would put a 60% probability that by 2032 Google will have embraced language models to offer AI generated content as their main result. This will likely increase AI-intensity, but Google has enough fat so they don’t lose a lot margins, if any margin at all. Google semiconductor endeavors will be of increased importance, not only to cut middle main profits and procure them directly from Samsung, but also to create cornered resources.
Here at MetaCritic Capital, we will stay vigilant: Sam is working hard to improve.

This also doesn’t mean you should sell the stock. If you think that if things go well, Google is worth $1.50 on the dollar, even if there’s a 1% probability you lose all, it’s still a nice proposition.
A consumer electronics company that fits this pattern was Oculus. One option is that Facebook has wrongly pattern-matched, but the other option is that companies with strong social network effects, even if they’re outside of the consumer internet, can also be very valuable without any revenue.
In art industries, there are many views of what makes something good or bad, each consumer has its own. Also, people may want to consume bad content on purpose. The comparison is that in order to compete, Netflix had to make only one movie that is funny, smart, beautiful, appeals to kids, adults, teens… Instead, Netflix can start making just one show for political nerds.
A scenario where Google can’t make a search engine to run on Android because someone else has better AI is short-lived, because it would soon be followed by singularity and then AI Apocalypse. So you should interpret my comment more as a unlikely outcome that helps to clarify Giogle’s business than something that would actually happen.
There’s speculation that GPT-4 will be 100T parameters. Even if that’s not the case, it inevitably will. Eventually, hard coding the parameters into silicon so that you can solve the entire problem in just one clock will become a reality, in my opinion.