Recursive self-improvement
How investors can start to get line of sight to recursive self-improving artificial intelligence

Didn’t see this argument laid out anywhere. It’s worth the time laying it out here.
Recently, OpenAI Co-founder and former Head of AI at Tesla, Andrej Karpathy, posted this on X dot com:

From LessWrong (October 2025):
In early 2024 Andrej Karpathy stood up an llm.c repo to train GPT-2 (124M), which took an equivalent of 45 minutes on 8xH100 GPUs to reach 3.28 cross entropy loss. By Jan 2025, collaborators of modded-nanogpt brought that time down to 3 minutes. It sat near 3 minutes until July 2025, having a large swath of optimization already applied: RoPE, value embeddings, reduce scatter grad updates, Muon, QK Norm, Relu^2, a custom FP8 head, skip connections, flex attention, short-long windows, attention window warmup, linear lr cooldown, and more. Yet, in the last 3 months the record has fallen by another 20% to 2 minutes and 20 seconds.
Nanochat is the spiritual successor to NanoGPT, that includes more than just Pre-training. Nanochat and NanoGPT both show a very important idea: in the years since 2019, it’s substantially cheaper and faster to train GPT-2:

Two things are remarkable:
Karparthy alone is capable of training GPT-2 at ~1% of the cost OpenAI did in 2019, despite OpenAI having its entire corporate power behind it.
Karparthy’s agent swarm running unassisted for three days was capable of breaking Karparthy’s world record by making changes to the code that it runs ~10% faster.
Think about the significance of it. The machine was capable of making changes to LLMs that one of the world’s best computer scientists didn’t do and in doing so, created cheaper AI.
I want to make two claims:
The price decline of inference, for a fixed amount of intelligence, will not stop declining 70-90% per year, and the balance of risks points towards an acceleration.
That’s the mechanism of recursive self-improvement.
Price declines

At launch, 1M tokens of GPT-3 costed roughly $50. If Ark forecasts are to be believed, and I think they are1, by 2030, we might be looking at a situation where the training costs of GPT-3 are cheaper than the inference cost of 1 million tokens at launch.
It seems we are only at the beginning of this price curve, as we only put a proper agent swarm in place this week to optimize the training costs of GPT-2.
Inference-time scaling
It is somewhat well known that by increasing the amount of reasoning you do in a LLM, you can improve performance predictably. See ARC-AGI-2:
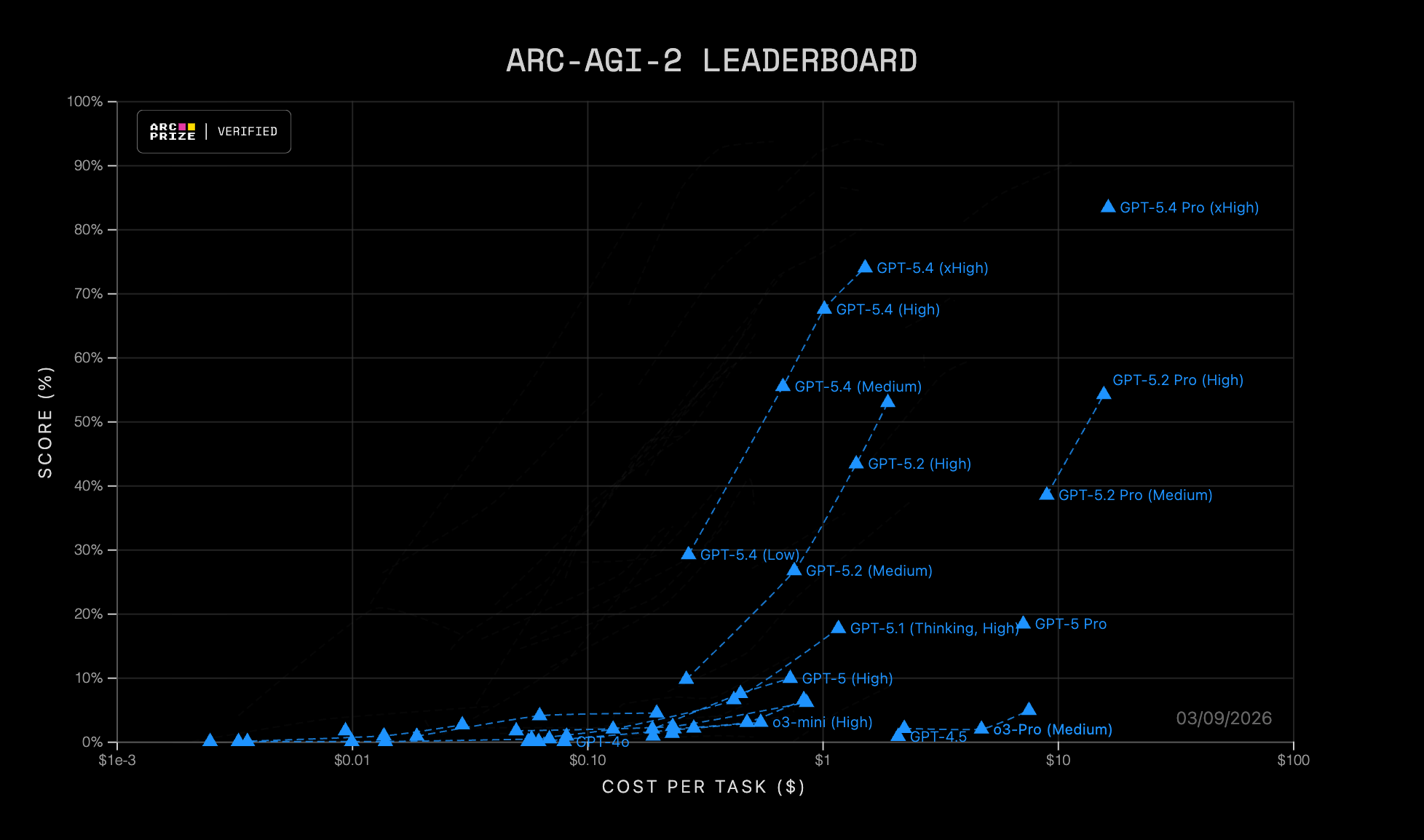
You can, with some effort, “crystalize” those inference-time scaling gains through reinforcement learning. That’s a good chunk of the story of OpenAI models in the ARC-AGI-2 leaderboard. Notice that models consistently move left, but for the same model, increasing the reasoning amount improves performance on the benchmark.
One might wonder: what would happen if OpenAI decided to run GPT-5.4-extra-extra-high at ten dollars per task? It’d probably hit 80-85% performance. Just by glancing at the chart.
It doesn’t seem very economical. Sure, the move from 20 cents per task to $1.2 per task is substantial, but it is also reflected in the improvement in score. People are willing to pay more for that, so OpenAI releases the model.
Basically, if models are 10x cheaper, you can predictably run them at 10x more reasoning tokens and get predictably more intelligence.
And if you do that a lot in things with verifiable rewards, you can just keep iterating.
Price declines fuel the recursive self-improvement
One way to think about perpetually running agent swarms is that they are quite bad at creating new stuff, but they are good at doing things that are verifiable and just improving them.
Such is the case of GPT-2: the world has known how to create GPT-2 for eight years now. We have very good benchmarks to determine whether a program is GPT-2 or not. This makes this problem well-suited to be run in a perpetually improving agent swarm: it doesn’t need to create more intelligence; all it needs to do is make it cheaper. That’s an easier problem.2
But now that you have cheaper intelligence, you can increase the inference tokens, you can create intelligence out of thin air, you can crystallize it through Reinforcement Learning with Verifiable Rewards, repeat.
Takeaways from investors

This realization makes me even more spooked by the sheer magnitude of price declines. While some people like to handwave with Jevon’s, the AI trade would be massively different today if all that OpenAI, Anthropic, and Google DeepMind were doing was selling GPT-4 tokens at 99.5% of the cost.

Pay attention, this is a post that is positive about capabilities. I think we finally have line of sight to how recursive self-improvement happens.
The following question we get then is: if Anthropic puts Claude Opus 4.6 in an agent swarm to train a Claude Opus 4.6 faster and cheaper, and it enables them to recursively make Opus 1,000x cheaper, so that we can run reasoning at 1,000x more tokens, will there still be enough interesting things to be discovered?
Maybe.
At the same time, the subjects to benchmark will increasingly be circlejerks that can be improved forever but have little connection to reality. GPT-5.4 is much better in mathematics, but elo rating in the arena of human eval has decelerated substantially3.
In the fullness of time, I believe that Jevon’s Paradox is extremely overstated, and the extent to which cost declines enable more intelligence is extremely understated.

In summary:
We have line of sight to how a RSI mechanism would be: price decline → inference-time scaling → Reinforcement-learning with verifiable rewards (RLVR)
If (economically significant) capabilities were to hit a wall, the extent of token-cost deflation is substantially greater than I previously considered.
Once again: AI is the perfect bubble.4
GPT-3 is roughly 2-3 orders of magnitude more expensive than GPT-2. And we still have five years until 2030.
I am well aware that Nanochat is a training cost benchmark. But it’s absolutely reasonable to think you can do the same thing for inference costs.
To my surprise, the acceleration in the Epoch Capabilities Index and the METR Chart is 10-100x more discussed than the deceleration in the LMArena. I showed this draft to Claude, and he argued that this is an argument against RSI. Maybe. But for some things, like training humanoid robots or programming, it seems we can continue to improve a lot with verifiable rewards. This is important to realize the tension in how the number of things that can get better grows, while the air around it gets rarer.
Hopefully, AI is the perfect bubble will be a future post.